CLIP: Multi-modality and Zero shot image classification 📸


Ismael Coulibaly / January 29, 2024
7 min read • ––– likes

Hello friends! Woke up fully enthousiastic about Neural Networks 🧠 we are going to learn about the multimodal learning paradigm. Inspired by OpenAI's CLIP: Connecting text and images.
I will explain to you what is Multimodality in general, how it has been done in the above paper, why is it beneficial and with the cherry on the top I will provide an interative demo 🤓.
Introduction
Dive into the captivating realm of the human brain and its extraordinary processing abilities! Picture our intricate brains as versatile neural networks, decoding a myriad of sensory data through electrochemical signals. As technology advances, the evolution of multi-modal models is transforming the landscape of search capabilities. Imagine a world where AI seamlessly integrates audio, visuals, smells, tastes, and touch, revolutionizing the accuracy and relevance of our searches. Join the excitement as we explore the fascinating frontier of multi-modal search, unlocking new possibilities and pushing the boundaries of what's possible!
Multimodal ML ?
Advancing beyond renowned language models such as BERTs and T5, we have transcended large text-only datasets by delving into extensive multi-modal datasets, incorporating information from diverse media forms like images, text, sounds, etc.
Recognising the world's multi-modal nature, encompassing language, imagery, video, smell, touch, and more, is pivotal. Our perception of the world is akin to an orchestra of sensory modalities, generating an internal model of the external environment.
For AI to progress, even specialised models concentrating on language or vision must eventually incorporate input from other modalities. For instance, understanding the concept of "person" requires visual input. This done for example by Tesla auto driver cars combining visual and sensory data to make sense of the surroundings, and Midjourney, which can make pictures out of text descriptions.
CLIP ?
Text and image encoding
It is important to note that CLIP uses two modalities, being text and image. The above multi-modal functionality is driven by two encoder models meticulously trained together to "understand each other" Textual inputs undergo processing by a text encoder, while image inputs are handled by an image encoder. Subsequently, both models generate a vectorised representations corresponding to their respective inputs.
The essence of "understand each other" lies in the convergence of these models to encode analogous concepts in both text and images into comparable vectors. In practical terms, if presented with the textual input "A fluffy winter read coat for woman" the model would generate a vector closely resembling that produced by an image depicting a woman wearing a winter coat that has a fluffy texture and a red colour.
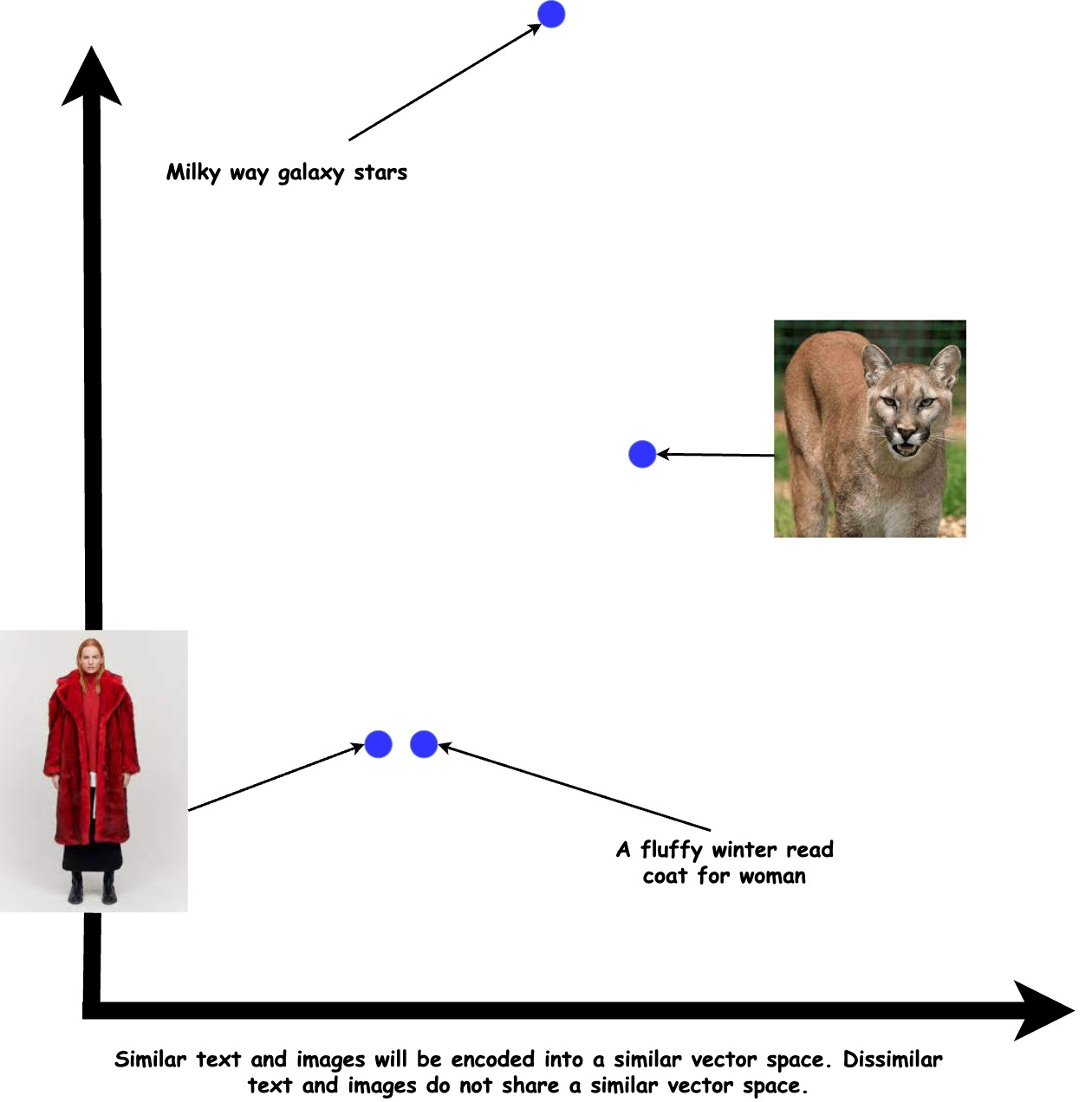
The language employed by both models (text and image encoders) can be seen as the vector space in which they encode vectors. Within this vector space, the two models have the ability to articulate nuanced information about both text and images.
Instead of directly interpreting this "language," an alternative approach involves training simpler neural networks to grasp it and generate predictions intelligible to humans. Alternatively, vector search techniques can be employed to recognise similarities in concepts and patterns spanning text and image domains.
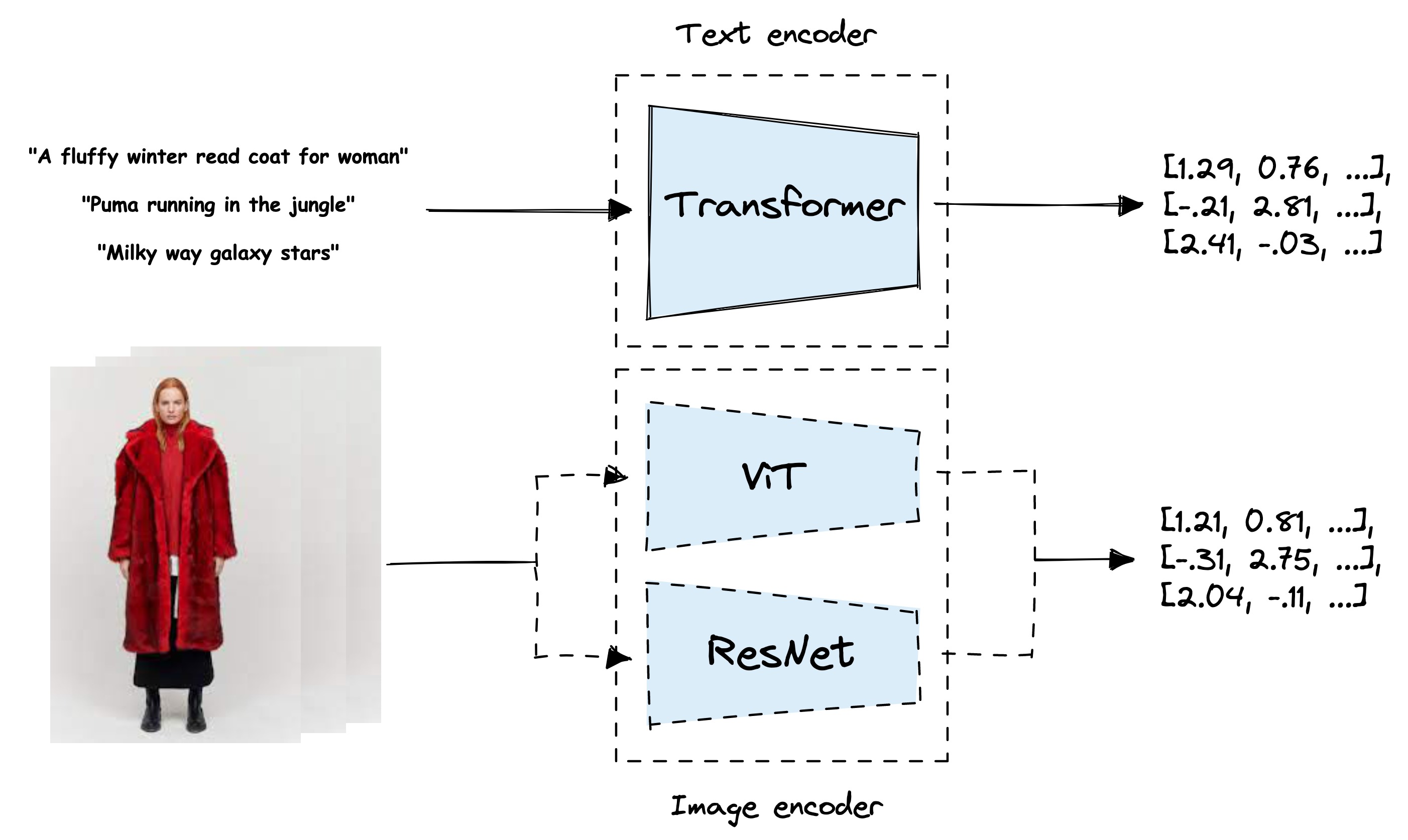 Architecture diagram of CLIP with the text encoder and ViT or ResNet as the image encoder.
Architecture diagram of CLIP with the text encoder and ViT or ResNet as the image encoder.
Contrastive Learning
For language models, this involves understanding the overarching rules and patterns of the English language, while for vision models, it pertains to recognizing the characteristics of various scenes or objects. However, a challenge arises in dealing with multimodal models, as they are traditionally trained independently and lack mutual comprehension.
CLIP addresses this challenge through image-text contrastive pretraining. It facilitates the training of text and image encoders, taking into account the context and modality of the other. Consequently, text and image encoders develop an "indirect understanding" of patterns in both language and vision.
The core mechanism of contrastive pretraining involves encoding (text, image) pairs, where the text describes the image, to be as close as possible in vector space. This process requires positive pairs that yield similar vectors and negative pairs that result in dissimilar vectors.
Contrastive learning, a prevalent technique found in the training functions of various models, involves creating negative pairs by swapping components of positive pairs. For instance, if we have positive pairs (T1, I1) and (T2, I2), the corresponding negative pairs would be (T1, I2) and (T2, I1). The training objective is to maximize similarity between positive pairs and minimize similarity between negative pairs, forming the basis for the loss function.
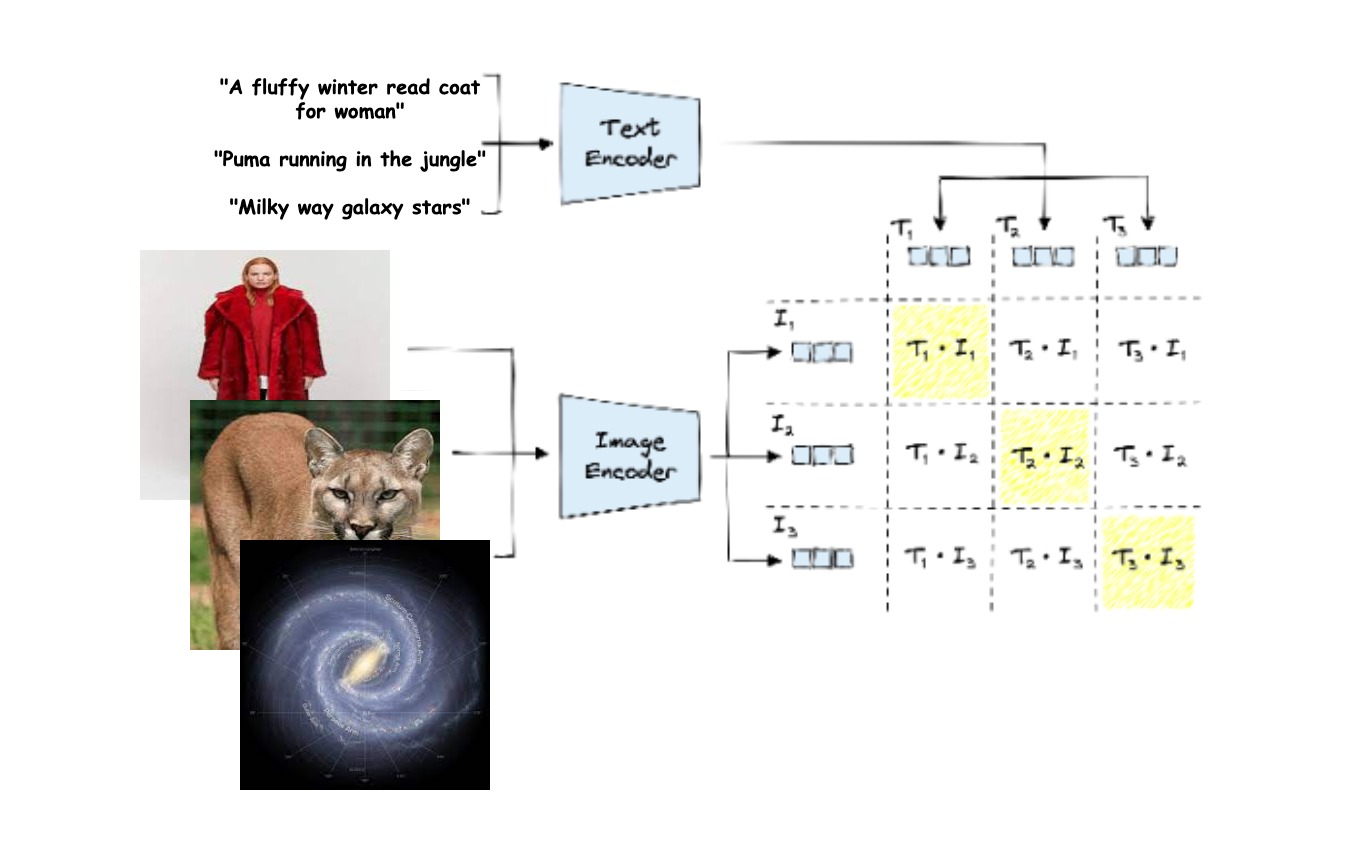 Contrastive pretraining with CLIP.
Contrastive pretraining with CLIP.
In the above illustration, the loss function operates on the premise that pairs on the diagonal should have an optimised dot product score, while all other pairs should exhibit a minimised dot product score. Both the text and image encoder models are fine-tuned accordingly.
A key assumption underlying this process is the absence of additional positive pairs within a given batch. Specifically, it is presumed that phrases like "A fluffy winter read coat for woman" are exclusively associated with the image they are paired with, with no other texts or images possessing analogous meanings.
This assumption is feasible due to the diversity and size of the datasets utilised in pretraining, making the likelihood of similar pairs emerging in a single batch exceptionally low. As a result, any potential negative impact on pretraining performance is deemed minimal or nonexistent.
Effective Zero-Shot whith CLIP
Zero-Shot learning?
Zero-Shot learning is a pivotal concept in machine learning and unlike N-shot learning, which requires a specific number of training samples for predictions in a new domain or task, zero-shot learning presents an ideal scenario where no training samples are needed. In contrast to traditional N-shot learning, where models like ResNet or BERT undergo extensive pre-training and subsequent fine-tuning for specific tasks with a substantial number of training samples, zero-shot learning, eliminates the need for any training samples when transitioning to a new domain or task. This advancement reduces dependence on compute power, time, and extensive data during the fine-tuning process.
Zero-Shot Classification with CLIP
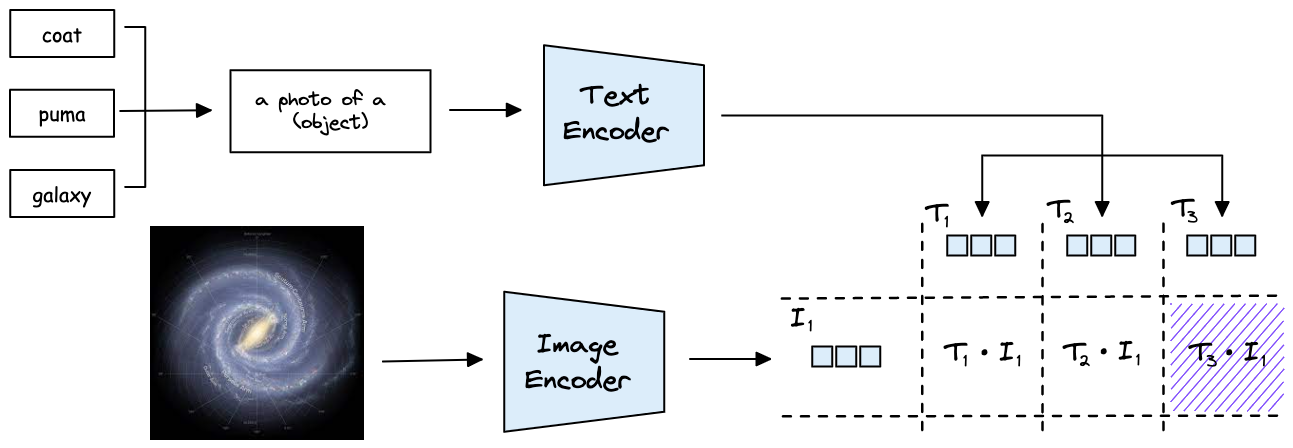
How do we achieve zero-shot classification with CLIP?
By creating vectors for images and text within the same vector space alignment. If we represent dataset classes as text sentences, such as "a photo of a coat," "a photo of a puma," and "a photo of a galaxy," each class is encoded as vectors (T₁, T₂, T₃) by the text encoder. When given a photo of a galaxy, encoded as vector I₁ by the ViT model, calculating their similarity with cosine similarity, we anticipate the highest score for similarity(T₃, I₁).
Demo: Clothing Search Engine
This part of the article is dedicated to a practical use-case of CLIP Zero-Shot classification. It convers the implementations of the CLIP inference (text and image embeddings generation), Vector database manipulation (saving and retrieving), building and deployment of the self-contained app.
The goal is to have a clothing search engine, on which we will be able to look for cloths either through prompting text in a research bar and/or by uploading an image of a cloth. We'll use the fashion-product-images-small by Ashraq from the Hugging-Face datasets. The Bm25Transformer is used as text encoder whereas the preference was done with ViT (Vision Transformer) as image encoder. Furthermore, as for the vector database, Pinecone is very useful for it's free api-key plan for experimentation purpose. The app user interface is seamlessly build with gradio and deploy huggingface space. For computation purpose, huggingface space may sometimes be slow during the demo due to the low cpu memory provided on the free space plan. In case, the space's demo is to slow, a google colab notebook is provided to make the experience way more faster faster with free GPU 😜
Try out the Demo or run the Colab Notebook